




Por Encarnación Folgado
Se puede definir la Visión Artificial como un campo de la Inteligencia Artificial que, mediante la utilización de las técnicas adecuadas, permite la obtención, procesamiento y análisis de cualquier tipo de información especial obtenida a través de imágenes digitales.
La Visión Artificial como rama de la Inteligencia Artificial ha evolucionado mucho en los últimos años gracias al desarrollo de técnicas basadas en redes neuronales artificiales (nodos de conexión que simulan el cerebro humano, fig.1 ). Dentro de estas técnicas están un tipo de redes neuronales denominadas: Redes Neuronales Profundas o Deep Learning. Estas redes profundas son una técnica que imita la forma de aprendizaje humano utilizando algoritmos y que se componen de diferentes niveles jerárquicos o capas. Por tanto, el Deep Learning sigue un proceso por capas que simula el funcionamiento básico del cerebro que se realiza a través de las redes de neuronas.
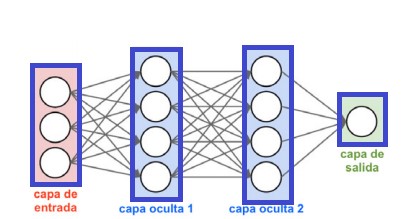
Fig.1 Imagen de una Red Neuronal.
Últimamente, diferentes universidades del mundo han desarrollado algoritmos capaces de trabajar de manera cada vez más avanzada en aspectos de la Visión Artificial. A finales del año pasado se hablaba de una red neuronal que generaba caras de personas que no existen con resultados extraordinarios, dichos algoritmos se conocen como GANs o Generative Adversary Networks que, en español, quiere decir Redes Generativas Antagónicas.
Las GANs pueden generar y desarrollar rostros humanos falsos. Gracias a estas redes se pueden desarrollar rostros casi hiperrealistas que no se corresponden con ninguna persona real.
Las redes generativas antagónicas se sustentan en el enfrentamiento de dos redes neuronales que compiten en un juego continuo. Es decir, la pérdida o ganancia de una de esas redes se compensa con la pérdida o ganancia de la opuesta.
Una de las redes neuronales de que se componen las GANs se denomina: generadora, esta red aprende de un gran número de imágenes de personas a generar las suyas propias. Una vez las ha generado las envía a otra red llamada: discriminadora, la cual ha sido entrenada previamente con el fin de que sea capaz de determinar la apariencia que tiene la imagen de la persona. La red discriminadora califica cada una de las imágenes de la red generadora en función del realismo de la misma. Con el tiempo, el generador va mejorando su tarea de producir imágenes falsas, y el discriminador mejora a la hora de detectarlas.
El gran avance de estas redes es que después de un entrenamiento inicial, continúan aprendiendo sin supervisión humana. Esto las hace muy interesantes para las posteriores investigaciones que están teniendo lugar dentro del campo de la Visión Artificial en los últimos tiempos.
Utilizando las GANs, una de las últimas investigaciones de este año 2019 en Visión Artificial, consiste en replicar imágenes de caras vistas o imaginadas por personas. Es decir, han utilizado las GANs para decodificar pensamientos y replicar en una red neuronal artificial las caras que veían o imaginaban de personas, mientras sus cerebros eran observados con imágenes de resonancia magnética. Es decir, no sólo estamos hablando de Visión Artificial, si no de Visión Artificial unida a la consciencia de los humanos.
Para conseguirlo, Los investigadores recurrieron a GANs, capaces de generar rostros de personas que no existen, para conseguir la multiplicación de las caras originales presentadas a la red neuronal artificial. Esto lo consiguió utilizando imágenes generadas por la actividad cerebral obtenida de los voluntarios mediante resonancia magnética la cual permite generar imágenes de las regiones cerebrales activas cuando se está ejecutando una determinada tarea, en este caso ver la cara de una persona.
El sistema pudo comparar miles de caras presentadas a los voluntarios en el experimento, con las imágenes de caras representadas en la red neuronal artificial. A continuación, tradujo los patrones de resonancia magnética de los cerebros humanos y replicó las caras que veían los participantes del experimento.
No sólo este sistema consiguió lo anteriormente comentado, sino que, además, el sistema fue capaz de reconstruir caras por sí mismo, aunque los voluntarios de la investigación no estuvieran viendo ninguna, sino solo imaginándola con un porcentaje de acierto por encima del 75%.
Este sistema de IA, que puede leer y comprender la información sensorial presente en el cerebro, ayudará a resolver muchas cuestiones pendientes en neurociencia sobre el tratamiento neuronal de las caras. Por tanto, este nuevo estudio de investigación dentro de la Visión Artificial puede compararse con las representaciones que realiza el cerebro humano para aprender, que usa la abstracción (representación de una cara) para construir conocimiento, es decir nuevas caras, a partir de un concepto o idea anterior.
Áreas de la visión Artificial hoy en día
En los últimos años, los sistemas de Visión Artificial han evolucionado tanto tecnológicamente como en la propia filosofía del sistema de visión. Esto ha implicado cambios sustanciales en la forma de interpretar la visión como una herramienta estándar para el análisis de procesos. Utilizando las diferentes técnicas: reconocimiento, detección y segmentación se han conseguido aplicar a diferentes campos según tipo de industria:
- Automoción: equipos de inspección en la fabricación y ensamblaje.
- Alimentos y bebidas: control de calidad de producto y packaging primario, secundario y terciario.
- Electrónica: equipos de inspección de fabricación y ensamblaje de piezas.
- Logística: equipos de inspección para el control de embalaje y trazabilidad.
- Farmacéutica: equipos de control de calidad e inspección en productos, serialización, trazabilidad, empaquetamiento.
- Transporte / Guiado de vehículos.
- Identificación facial, Biometría.
- Industria del cine.
- Inspección de calidad en materiales como la madera.
- Sistemas 3D (Gafas)
- Aplicaciones de tráfico.
- Marketing.
- Ocio y entretenimiento.
Etapas de la visión Artificial
La visión artificial lleva un conjunto de etapas:
- El primer paso en el proceso es adquirir la imagen digital. Para ello se necesitan sensores y la capacidad para digitalizar la señal producida por el sensor. Una vez que la imagen digitalizada ha sido obtenida, el siguiente paso consiste en el preprocesamiento de dicha imagen. Cuyo objetivo es mejorar la imagen de forma que el objetivo final tenga mayores posibilidades de éxito.
- El paso siguiente es la segmentación, siendo su objetivo es dividir la imagen en las partes que la constituyen o los objetos que la forman.
- Posteriormente, es necesario convertir estos datos a una forma que sea apropiada para el ordenador. La primera decisión es saber si se va a usar la representación por frontera (bordes) o región completa. La representación por la frontera es apropiada cuando el objetivo se centra en las características de la forma externa como esquinas o concavidades y convexidades. La representación por regiones es apropiada cuando la atención se centra en propiedades internas como la textura o el esqueleto. Sin embargo, en muchas aplicaciones ambas representaciones coexisten.
- Finalmente, es el reconocimiento y la interpretación. El reconocimiento es el proceso que asigna una etiqueta a un objeto basada en la información que proporcionan los descriptores (clasificación). Mientras que la interpretación lleva a asignar significado al conjunto de objetos reconocidos.
VISION COMPUTADOR vs VISION HUMANA
Lo primero que hay que decir es que dotar a las máquinas del futuro de una visión similar a la humana es uno de los grandes retos de la rama de la Inteligencia Artificial llamada Visión Artificial.
Mientras que la visión humana es más adecuada para la interpretación en cuanto a la calidad de escenas complejas no estructuradas. La tarea de interpretar las imágenes que después realiza el cerebro tampoco es trivial. Se trata del proceso que más recursos consume de nuestro cerebro, ocupando casi el 50% del total, haciendo muchas funciones y muy variadas, como por ejemplo, interpretar qué objetos hay, que texturas, a qué distancia están las cosas, cuál es la imagen a partir de lo que recibe de ambos ojos, cuál es la dirección del movimiento, si lo hay, y crear imágenes nítidas a partir de varias, etc., todo ello a una velocidad casi instantánea.
la Visión Artificial es más eficiente al procesamiento en cantidad de escenas estructuradas gracias a su velocidad, precisión y repetibilidad. Por ejemplo, en una línea de producción, un sistema de visión artificial puede inspeccionar cientos, o incluso miles, de piezas por minuto. Un sistema de visión artificial gira en torno a la resolución correcta de la cámara y a la óptica que le permiten inspeccionar fácilmente detalles de un objeto demasiado pequeños para que el ojo humano pueda llegarlos a ver.
Una vez que tengamos algoritmos rápidos, equivalentes a los que realiza el cerebro y dispongamos del hardware que permita ejecutar esos algoritmos en poco tiempo, será necesario combinar toda esa información para conseguir una visión artificial como la humana. Otra diferencia importante sería que una máquina probablemente no estaría sujeta a los errores que comete el cerebro. El cerebro humano por evolución se ha adaptado a situaciones habituales que se dan en el mundo real, para optimizar la rapidez con que procesa las imágenes, por eso nuestro cerebro, en ocasiones, nos muestra incorrectamente la realidad.